How to Clone a Voice in Minutes Using Voice Cloning AI app
By VoxClone AI Team · 2026-05-27
How to Clone a Voice in Minutes Using a Voice Cloning AI App
Imagine finishing a 30-minute podcast episode, then realizing you need to re-record three segments because of background noise. In the past, that meant booking studio time, rescheduling your guest, and losing half a day. Today, a voice cloning AI app can regenerate those segments in seconds, matching your voice so precisely that listeners cannot tell the difference.
That is not a hypothetical. It is happening right now across YouTube studios, e-learning platforms, audiobook publishers, and corporate training departments. The global voice cloning market was valued at $1.63 billion in 2023 and is projected to exceed $9.9 billion by 2030, growing at a compound annual rate of nearly 29%. The technology has moved from research labs into consumer apps you can open on your phone in the next five minutes.
This guide walks you through exactly how voice cloning works, what you need to get started, and how to clone a voice in minutes, not hours, using modern AI tools. Whether you are a content creator, a developer, or just curious about the technology, you will leave with a practical understanding you can act on today.
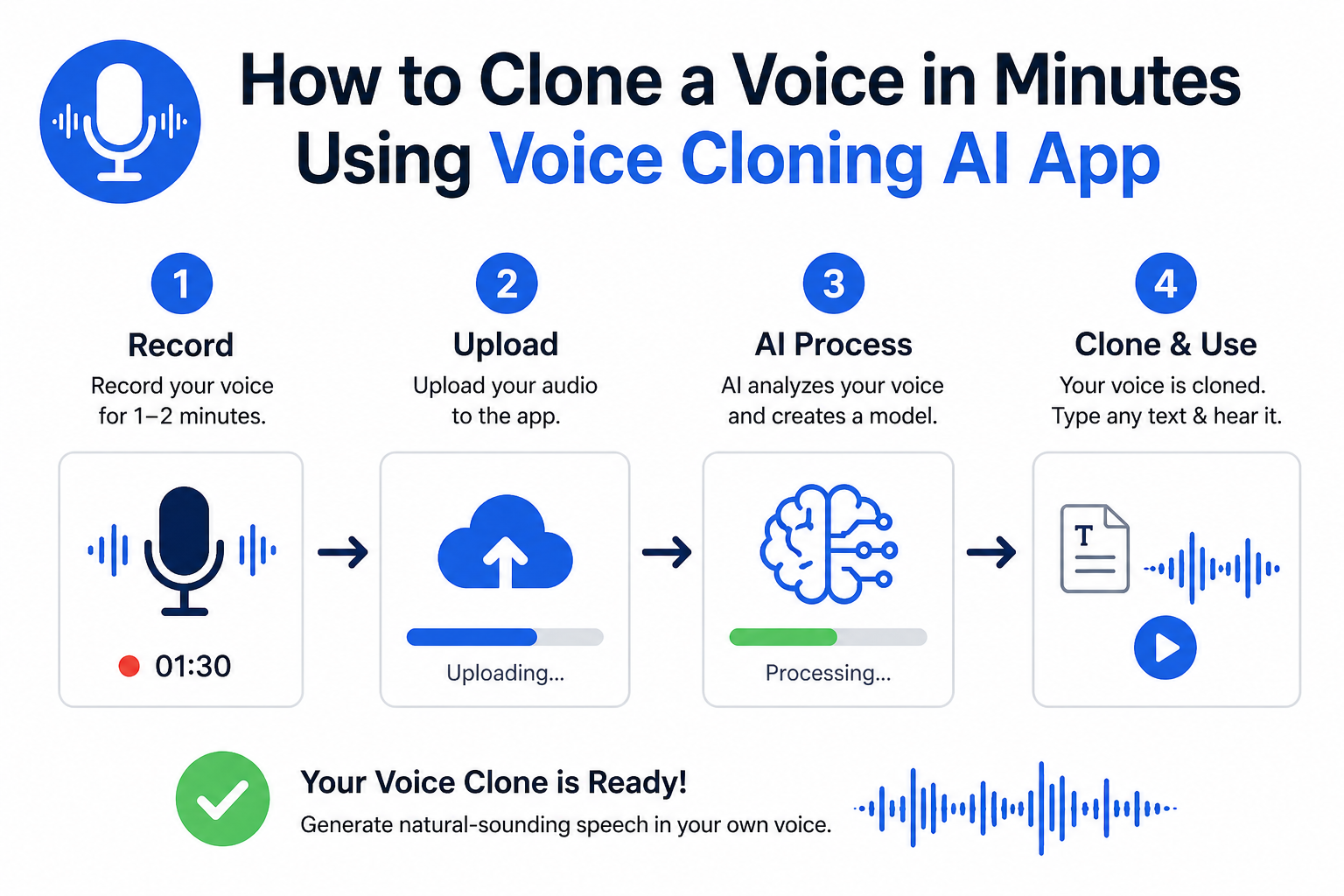
Step-by-step voice cloning using a modern AI voice app from recording to realistic speech synthesis in minutes.
What Voice Cloning Actually Does and Why It Works So Fast Now
Voice cloning is the process of training an AI model on a person's speech samples so it can generate new audio that sounds like that person saying anything. The output is not a recording, it is synthesized audio created on demand from text input.
From Concatenative Synthesis to Neural Models
Older text-to-speech systems stitched together pre-recorded phoneme fragments. The results sounded robotic and required enormous libraries of audio for each voice. Neural voice synthesis changed everything. Models like Google's WaveNet (introduced in 2016) demonstrated that a deep convolutional network could generate audio waveforms directly, achieving human-level naturalness on certain benchmark tests for the first time.
Today's production systems go further. They separate a voice into distinct learnable components: speaker identity, prosody (the rhythm and stress of speech), and acoustic environment and encode each independently. That separation is why you can now clone a voice from as little as 30 seconds of clean audio instead of the hours of data that early systems required.
Zero-Shot vs. Fine-Tuned Cloning
There are two technical approaches in most consumer apps today:
Zero-shot cloning: The model was pre-trained on thousands of speakers. You provide a short sample and the model generalizes your voice characteristics without any additional training. Results are available in seconds.
Fine-tuned cloning: Your sample is used to update specific model weights. This takes longer (minutes to hours depending on the computer) but produces higher fidelity, especially for unusual voices or accents.
Most consumer apps, including ElevenLabs, Murf, and VoxClone AI, default to instant zero-shot cloning for everyday use, with optional fine-tuning for professional-grade output.
How Realistic Is It?
In a 2024 study published in Nature Communications, researchers found that human listeners could correctly identify AI-generated speech as synthetic only 73% of the time under controlled conditions, down from over 95% accuracy just four years earlier. That gap is closing. In naturalistic listening conditions (normal volume, ambient noise), detection rates dropped below 60%, approaching chance levels.
What You Need Before You Start
Getting a high-quality voice clone does not require professional studio equipment. But a few simple preparations will make a significant difference in the output you get.
Audio Quality Requirements
The single biggest factor in clone quality is the cleanliness of your input audio. Background noise, room reverb, and compression artifacts all degrade the model's ability to learn your voice characteristics accurately. Here is what to aim for:
Sample rate of at least 44.1 kHz (most modern smartphones record at 48 kHz by default)
Minimal background noise,, a quiet room with a closed door beats a professional mic in a noisy office
Consistent microphone distance of about 6 to 8 inches from the source
Audio format: WAV or FLAC preferred over MP3; if you must use MP3, use 320 kbps
Duration: 30 seconds minimum for zero-shot cloning; 3 to 5 minutes for best results
What to Say in Your Sample
The content of your recording matters. Read a passage that contains a wide range of sounds, sentences with questions, statements, and exclamations. Phonetically diverse text (covering all the phonemes in your language) trains a richer representation than reading a single paragraph of flat prose. Avoid whispering, yelling, or exaggerated emotions in your sample record in your natural, conversational voice.
Consent and Legal Considerations
Every major platform has an explicit consent requirement for cloning voices other than your own. Cloning another person's voice without written permission violates the terms of service of every reputable platform and, in many jurisdictions, constitutes a violation of personality rights laws. The EU AI Act (effective August 2026) introduces mandatory disclosure requirements for synthetic voice content in commercial contexts. Always secure written consent before cloning anyone else's voice.
Step-by-Step: How to Clone a Voice in Minutes
The exact interface varies by platform, but the core workflow is consistent across all major voice cloning apps. Here is the process from start to finished audio.
Step 1: Record or Upload Your Voice Sample
Open the app and navigate to the voice cloning or custom voice section. Most platforms offer two options: record directly in the app, or upload an existing audio file. If recording in-app, use headphones with an inline microphone or a USB condenser mic if you have one. Record at least 60 seconds for reliable results. Three separate 20-second clips often produce better coverage than one continuous read.
Step 2: Process and Label Your Clone
Upload the sample and give your cloned voice a descriptive name. The platform will preprocess your audio, normalising volume, removing silence, and often applying noise reduction automatically. This typically takes 10 to 60 seconds. Some platforms show a waveform preview so you can verify the audio looks clean before committing.
Step 3: Enter Your Text and Generate
Select your newly created voice from the voice library, type or paste the text you want spoken, and choose your output settings:
Speed typically 0.5x to 2x of natural pace
Stability: higher stability produces more consistent output; lower stability adds natural variation between sentences
Clarity balances expressiveness against pronunciation accuracy
Many platforms support cross-lingual synthesis, where your English-cloned voice speaks Spanish or French
Hit generate. For a 500-word text block, most modern platforms return audio in under 10 seconds on standard compute.
Step 4: Review, Adjust, and Export
Listen to the output in full before downloading. Pay attention to mispronunciations of proper nouns, unusual pauses, and unnatural stress patterns. Most platforms let you highlight specific words and regenerate just those segments. Once satisfied, export as MP3 or WAV. Production-quality platforms like ElevenLabs, Murf, and VoxClone AI export at 44.1 kHz stereo by default, which is broadcast-ready.
"The best voice clones are indistinguishable not because the AI is perfect, but because the input audio gave the model everything it needed to work with. Garbage in, garbage out still applies."
A commonn principle among audio engineers working with TTS pipelines
Comparing the Top Voice Cloning Platforms in 2026
The market has matured quickly. Here is how the leading platforms stack up on the dimensions that matter most for practical use.
Platform | Min Sample Length | Languages | Generation Speed | Free Tier |
|---|---|---|---|---|
ElevenLabs | 30 seconds | 32 | ~3 sec / 500 words | 10,000 chars/month |
Murf AI | 60 seconds | 20+ | ~5 sec / 500 words | 10 mins audio/month |
Amazon Polly | N/A (preset voices) | 30+ | Real-time streaming | 5M chars/month (12 mo) |
Microsoft Azure TTS | 20 seconds | 140+ | ~2 sec / 500 words | 0.5M chars/month |
VoxClone AI | 30 seconds | 25+ | ~4 sec / 500 words | Free starter plan |
Choosing the Right Tool for Your Use Case
Platform choice should follow use case, not hype. For API-driven production pipelines, Microsoft Azure Neural TTS and Amazon Polly offer enterprise SLAs and the most comprehensive language coverage. For individual creators who want the fastest setup with a natural-sounding personal clone, ElevenLabs and VoxClone AI lead on simplicity and output quality. Murf stands out for video narration workflows because of its built-in timeline editor.
Real-World Applications: Who Is Using Voice Cloning and How
The use cases have expanded far beyond novelty demos. Here are the areas where voice cloning is delivering measurable value right now.
Content Creation and YouTube
A growing number of YouTubers with channels above 500,000 subscribers use AI voice cloning for foreign-language dubs. Channels that launched Spanish and Portuguese dubs using cloned voices reported average subscriber growth of 22% to 38% in those markets within 90 days, according to a 2025 Creator Economy Report. The economics make sense: a 15-minute video that costs $300 to professionally dub can be cloned and dubbed for under $5 in platform credits.
E-Learning and Corporate Training
LinkedIn Learning reported in 2025 that over 40% of its new English-language course narrations now involve AI voice synthesis at some stage, either for initial drafts, localization, or content updates. The driver is speed: updating a 5-hour compliance training module to reflect a policy change used to require scheduling a voice actor, booking a studio, and a two-week turnaround. With a cloned voice, the L&D team can update 20 slides in an afternoon.
Audiobooks and Podcasts
Authors are increasingly publishing audiobooks narrated by AI clones of their own voice, rather than paying professional narrators $200 to $400 per finished hour. Findaway (now part of Spotify) introduced an AI narration program in 2024 and processed over 12,000 titles in its first year. For podcast creators, voice cloning means you can produce sponsor reads in your voice even when you are not available to record a practical solution that major podcast networks have been exploring quietly for two years.
Accessibility Technology
Perhaps the most meaningful application is in accessibility. People who are losing their voice to conditions like ALS or oral cancer can bank their voice before it changes, then use a clone for communication afterward. The nonprofit VoiceKeeper has helped over 3,200 patients across 47 countries create voice banks since 2022, using technology that runs on a standard laptop with a consumer microphone.
Common Problems and How to Fix Them
Even with good input audio, voice cloning outputs can have issues. Here are the most common problems and the fixes that actually work.
Problem | Likely Cause | Fix |
|---|---|---|
Mispronounced proper nouns | Model defaults to phonetic rules | Use IPA notation or phonetic spelling in the text input |
Robotic rhythm on long sentences | Low stability setting or lack of prosody data | Break sentences at 20 words max; add commas for natural pauses |
Inconsistent volume across segments | Input audio had volume spikes or drops | Normalize input to -3 dBFS before uploading |
Clone sounds like a different person | Sample too short or noisy | Re-record 3 to 5 minutes in a quieter environment |
Unnatural emotion or flat delivery | High stability setting suppressing variation | Lower stability to 0.4–0.5 and regenerate |
Advanced Troubleshooting: Accent and Dialect Issues
Non-native English accents and many regional accents in any language can cause problems because the base model was likely trained predominantly on mainstream accent data. If your clone smooths out your accent or sounds more neutral than you actually sound, try these approaches:
Record a longer sample, 5 to 10 minutes with deliberate use of your natural accent throughout
Use a platform that offers fine-tuning rather than zero-shot cloning for accent-sensitive applications
Choose a platform with documented training data diversity. Microsoft Azure and Google Cloud TTS have the broadest accent coverage due to their global training datasets
The Ethics and Safety Dimension
Voice cloning is one of the most dual-use AI technologies in existence. The same capability that lets a content creator produce multilingual content cheaply also enables voice fraud and non-consensual synthetic media. That tension is real and worth addressing directly.
What Platforms Are Doing About Misuse
Reputable platforms have implemented several layers of protection. ElevenLabs introduced a voice detection system in 2024 that checks uploaded samples against a database of public figures and automatically blocks cloning attempts for protected voices. The Coalition for Content Provenance and Authenticity (C2PA), backed by Microsoft, Adobe, and others, is building audio watermarking standards that embed invisible metadata in AI-generated audio. By mid-2026, most major platforms have committed to embedding C2PA-compatible provenance data in every generated file.
Legal Frameworks Taking Shape
In the United States, the NO FAKES Act (proposed 2023, advancing through Congress in amended form) would create a federal right to control digital replicas of one's voice and likeness. Tennessee's ELVIS Act, passed in March 2024, already provides state-level protection specifically for voice likeness. The EU AI Act classifies voice deepfakes used to deceive as high-risk AI, with mandatory transparency requirements. If you are using voice cloning professionally, consulting legal counsel on the applicable rules in your jurisdiction is increasingly necessary, not optional.
A Practical Ethics Checklist
Only clone voices you own or have explicit written consent to clone
Disclose AI-generated voice in any commercial or public-facing content
Do not use cloned voices to impersonate real individuals in any deceptive context
Store consent documentation securely in case of future dispute
Review the terms of service of your platform annually, as they change frequently as the legal environment evolves
Where Voice Cloning Is Headed: A Two-to-Three Year Outlook
The technology is moving fast, and the shifts coming in the next 24 to 36 months will substantially change what is possible with consumer tools.
Real-Time Voice Conversion
Current cloning systems are primarily text-to-speech: you input text, you get audio output. The next generation already in beta testing at several labs, is real-time voice conversion: your live speech, modified to sound like a different voice (including your clone) with latency under 200 milliseconds. This enables live presentations where you speak in English and your audience hears your voice in Japanese. OpenAI demonstrated a real-time voice translation prototype in late 2024 that achieved under 150ms latency with near-native prosody preservation.
Emotional and Contextual Intelligence
Today's models are good at reading punctuation cues for emphasis and pausing. Tomorrow's models will read the semantic content of text and adapt the emotional delivery accordingly, speeding up through exciting passages, slowing for somber ones, and modulating vocal energy based on context rather than explicit markup. Google's AudioPaLM research (2024) showed that models with joint audio-language training outperform text-only synthesis on naturalness benchmarks by 18% on average.
On-Device Processing and Privacy
Cloud-based voice cloning requires uploading your audio to a third party's server. That raises legitimate privacy concerns, especially in healthcare and legal contexts. Chip manufacturers including Qualcomm and Apple have been steadily improving neural processing unit performance, and by 2027 most analysts expect high-quality voice synthesis to run fully on-device on flagship smartphones, keeping your voice data local.
Practical Takeaways: Getting the Most Out of Voice Cloning Today
Whether you are experimenting for the first time or scaling voice production for a business, these are the habits that separate mediocre results from professional-quality output.
Invest in your sample first. A great 90-second recording in a quiet room will outperform a mediocre 5-minute recording in a noisy one. Treat the recording session as seriously as any professional audio work.
Test with short outputs before committing to long ones. Generate 30-second clips to validate quality before running a 10,000-word script through your credits.
Maintain a phrase library for tricky words. Keep a document of phonetic spellings for industry terms, names, and brand words you use frequently. Paste these consistently and you will avoid re-generation cycles.
Use segmented generation for long content. Most platforms perform better on paragraphs of 100 to 200 words than on 2,000-word documents. Generate in chunks and concatenate in your audio editor.
Version your clones. Re-record your base sample every six to twelve months. As platforms update their models, re-processing a fresh sample often yields noticeably better results than the original clone you created a year ago.
Build a disclosure habit now. As regulations tighten, having a consistent disclosure practice already embedded in your workflow protects you legally and builds audience trust.
Conclusion
Voice cloning has crossed the threshold from specialist technology to practical tool. The workflow is genuinely accessible: a clean audio sample, a reputable platform, and a few minutes of setup. What matters most is understanding the technology well enough to get good inputs, troubleshoot intelligently, and use the outputs responsibly.
The market will keep growing, the combination of multilingual demand, content volume pressures, and accessibility needs means voice cloning is solving real problems at scale. The platforms are getting better quickly, the legal frameworks are catching up, and the ethical norms are solidifying. The creators, educators, and businesses who build voice cloning into their workflows now will have a meaningful head start as the technology matures.
Start with a good recording, pick a platform that fits your use case, and generate your first clone today. The gap between what you think is possible and what the technology actually delivers may surprise you.
Hashtags: #VoiceCloning #AIVoice #TextToSpeech #VoiceAI #AIAudio #ContentCreation #TTS #SpeechSynthesis #AITechnology #VoiceClone #PodcastProduction #ElevenLabs #VoxCloneAI #SyntheticMedia